
NERF论文阅读
发布时间:
什么是NeRFs
1.神经辐射场 (\(NeRFs\))
神经辐射场 (\(NeRFs\)) 是指一套用于学习和表示物体或场景的深度神经网络。
辐射场:可以把它看做是一个函数,如果我们从一个角度向一个静态空间发射一条射线,可以查询这条射线在空间中每个点\((x,y,z)\)的密度\(\sigma\),以及该位置在射线角度\((\theta,\phi)\)下,呈现出来的颜色\(c(c=(R,G,B))\),即:\(F:(x,y,z,\theta,\phi)\rightarrow (R,G,B,\sigma)\)。其中密度是用来计算权重的,对点上的颜色做加权求和就可以呈现像素颜色,神经辐射场用深度神经网络来进行建模。
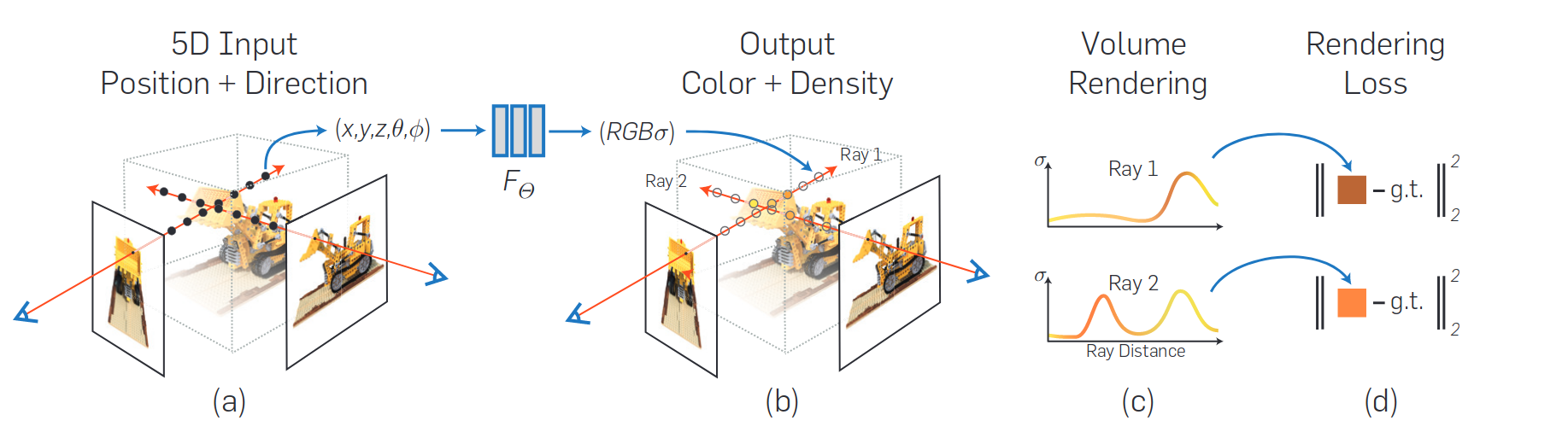
- 用network存体素信息:\((x,y,z,\theta,\phi)\rightarrow (c,\sigma)\)
- 然后用体素渲染方程获得生成视角图片:光线采样和积分
- 最后与原视角图片计算损失更新网络
具体来说,首先通过场景行进相机光线以生成采样3D点集;然后使用这些点及其对应的 2D 观察方向作为神经网络的输入,以产生颜色和密度的输出集;使用经典的体积渲染技术将这些颜色和密度累积到 2D 图像中。因为这个过程是自然可微的,可以使用梯度下降来优化这个模型,方法是最小化每个观察到的图像和从我们的表示中呈现的相应视图之间的误差。
\(F_{\theta}:(\mathbf{x},\mathbf{d})\rightarrow(\mathbf{c},\sigma)\),其中\(\mathbf{x}\)表示一个三维的一个位置,\(\mathbf{d}\)表示一个二维的观察方向。\(\mathbf{c}\)表示颜色,\(\sigma\)表示密度。
通过将高容量密度和准确的颜色分配给包含真实底层场景内容的位置,最小化跨多个视图鼓励网络预测场景的连贯模型的错误。
由于针对复杂场景优化神经辐射场表示的基本实现不会收敛到足够高分辨率的表示。通过使用使 MLP 能够表示更高频率函数的位置编码来转换输入 5D 坐标来解决这个问题。
2.体渲染
5D 神经辐射场将场景表示为空间中任意点的体积密度和定向发射辐射。使用经典体积渲染的原理渲染穿过场景的任何光线的颜色。
体积密度 \(σ(x)\) 可以解释为射线在位置 x 处终止于无穷小粒子的微分概率。具有近边界和远边界 \(t_{n }\)和 \(t_{f} \)的相机光线\( \mathbf{r}(t) = \mathbf{o} + t\mathbf{d}\) 的预期颜色 \(C(\mathbf{r})\) 是:
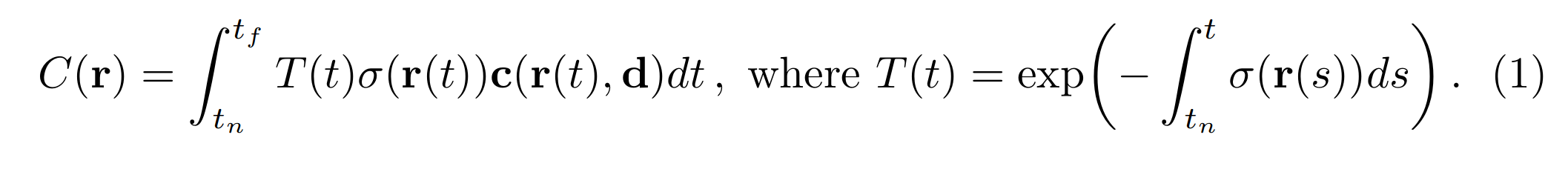
函数 \(T(t)\) 表示沿射线从 \(t_{n }\) 到 t 的累积透射率,即射线从 \(t_{n }\)传播到 t 而未撞击任何其他粒子的概率。
积分:
使用分层抽样方法,其中我们将\( [t_{n}, t_{f}] \)划分为 N 个均匀间隔的箱子,然后从每个箱子内随机均匀地抽取一个样本:
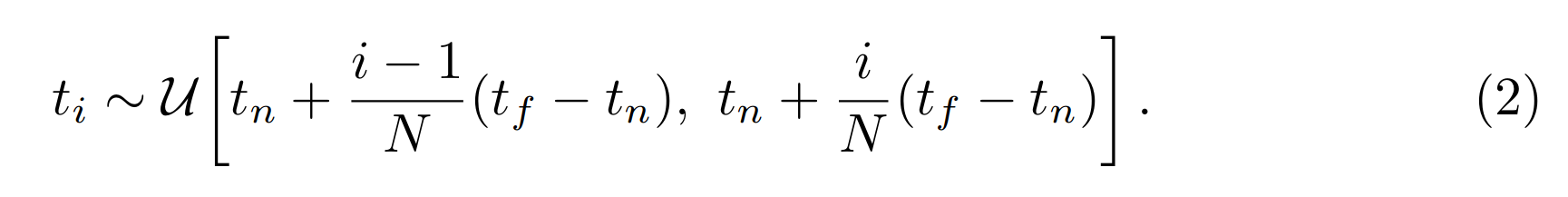
尽管我们使用一组离散的样本来估计积分,但分层采样使我们能够表示连续的场景表示,因为它会导致在优化过程中在连续位置评估 MLP。
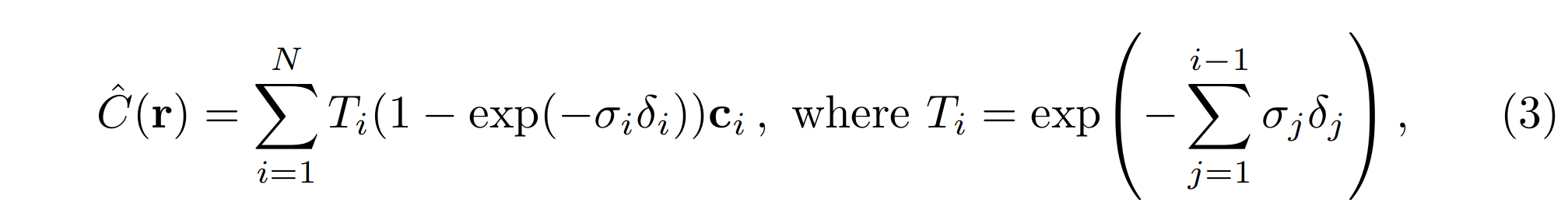
\(δ_{i} = t_{i+1} − t_{i}\)是相邻样本之间的距离。这个用于从一组 \((c_{i}, σ_{i})\) 值计算 \(C(r)\) 的函数是微分的,并且简化为具有 alpha 值 \(σ_{i} = 1 − exp(−σ_{i}δ_{i}) \)的传统 alpha 合成。
3.优化
引入了两项改进以实现高分辨率复杂场景的表示。
第一个是输入坐标的位置编码,帮助 MLP 表示高频函数。
第二个是分层体积抽样。
3.1 Positional encoding
尽管神经网络是通用函数逼近器,但让网络 \(F_{Θ}\) 直接在\( xyzθφ\) 输入坐标上运行会导致渲染在表示颜色和几何的高频变化方面表现不佳。Rahaman 等人最近的工作一致,On the spectral bias of neural networks
表明深度网络偏向于学习低频函数。他们还表明,在将输入传递到网络之前,使用高频函数将输入映射到更高维空间可以更好地拟合包含高频变化的数据。
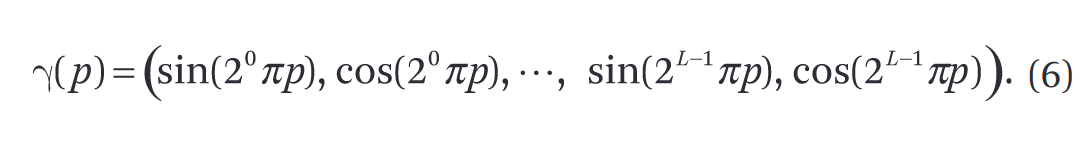
此函数 \(γ (·)\) 分别应用于 x 中的三个坐标值中的每一个(归一化为位于 [−1, 1] 中)和笛卡尔观察方向单位向量 d 的三个分量(通过构造位于在 [−1, 1]) 中。
\(F_{Θ}=F’_{Θ}\circγ\),一个学习,一个不学习,显着提高性能。

3.2 Hierarchical volume sampling
我们在沿每个摄像机射线的 N 个查询点处密集评估神经辐射场网络的渲染策略效率低下:对渲染图像没有贡献的自由空间和遮挡区域仍然被重复采样。
提出了一种分层表示,通过根据样本对最终渲染的预期效果按比例分配样本来提高渲染效率。
具体来说,提出了两个网络,一个粗略的网络用来计算比例,其实就是PDF(概率密度函数)。使用分层抽样对一组 \(N_{c}\) 位置进行抽样,并按照方程式中所述评估这些位置的“粗略”网络。
给定这个“粗”网络的输出,然后我们沿着每条射线产生更明智的点采样,其中样本偏向体积的相关部分。为此,首先重写方程式中粗网络 \(\hat{C}{c}(\mathbf{r})\) 的 alpha 合成颜色, 作为沿射线的所有采样颜色 \(c{i}\) 的加权和:
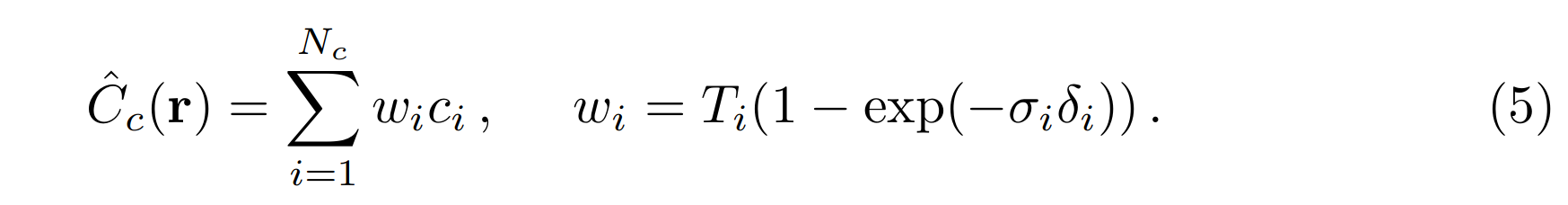
将这些权重归一化为 \(\hat{w}{i} = w{i}/∑^{N_{c}}{j=1}w{j} \)会产生沿射线的分段常数 PDF。
然后使用逆变换采样从该分布中采样第二组 \(N_f\) 个位置,在第一组和第二组样本的联合处评估我们的“精细”网络,并使用等式计算光线的最终渲染颜色 \(\hat{C}_{c}(\mathbf{r})\),但使用所有 \(N_c +N_f \)样本。此过程将更多样本分配到我们希望包含可见内容的区域。
4. 实验细节
损失函数:
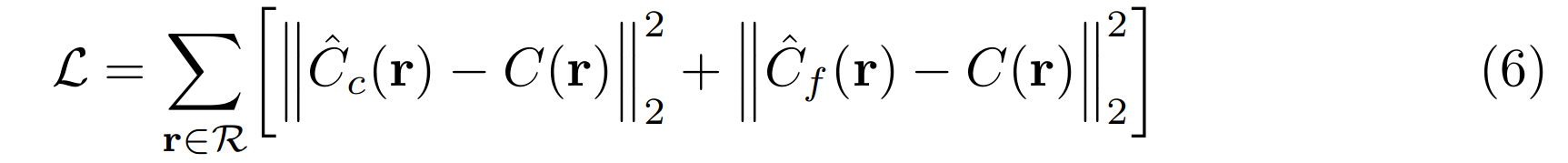
使用 4096 条射线的批量大小,每条射线在粗体积中的 \(N_c = 64 \)个坐标和精细体积中的 \(N_f = 128\) 个附加坐标处采样。我们使用 Adam 优化器 [18],其学习率从 \(5 × 10^4\) 开始,并在优化过程中呈指数衰减至 \(5 × 10^5\)(其他 Adam 超参数保留默认值 \(β1 = 0.9,β2 = 0.999,并且 = 10^7\))。单个场景的优化通常需要大约 100-300k 次迭代才能在单个 NVIDIA V100 GPU 上收敛(大约 1-2 天)。
5. 实验结果



发表评论